OPENING DOORS FOR PERSONALIZED MEDICINE
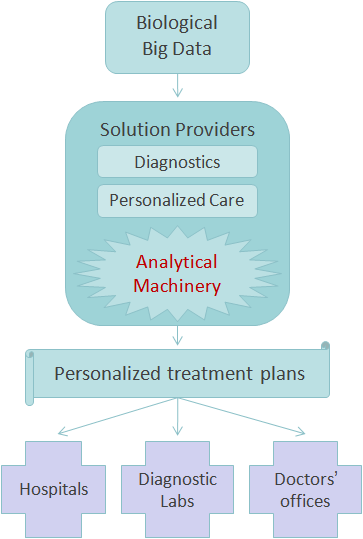
SciDMTM is a fast and flexible database engine for DNA sequences and other biomedical data, which can enable analytical machinery to efficiently process and deliver data in the desired format. For developers, it will mean no more BAM files. For medical practitioners and patients it will mean making personalized medicine a reality.
'Omics' data holds answers to therapeutic questions. Raw experimental data is converted into higher-level derived data: genotypes with variants, pathways, expression profiles, etc. It is too big for conventional relational databases, but requires relational database functionality to be efficiently used in biomedical applications.
Big Data tools do not provide the necessary granularity for biomedical analysis, and imply a considerable cost and maintenance overhead which can be avoided by using SciDM.
To enable medical applications, 'omics' data management must be:
- Fast: seconds/minutes per query vs. hours/days via standard SQL
- Focused: allow very specific queries across specific subsets of data
- Flexible: easily adjustable to handle new questions.
Please email us to request a whitepaper.